Nano4M-Audio extends the 4M encoder–decoder transformer (d6-6w512, ~96M parameters)
with audio as a fifth modality, tokenized via EnCodec with a MusicGen-style delay/flatten
pattern, and trained jointly with RGB, depth, surface normals, and a class caption under
Dirichlet masking — with contiguous span masking on the temporal audio
stream as the only training-side change to the recipe.
Summary
Recent multimodal foundation models like 4M unify vision and language under a single
masked-modeling objective. Yet audio — temporal, high-frequency, and acoustically rich —
remains conspicuously absent. We ask a precise question: can the 4M framework absorb audio
as a fifth modality at the scale of an academic project (~10⁴ paired clips, ~10⁸ parameters)?
We extend nano4M (~96M parameters) with audio via EnCodec tokenization, contiguous span
masking for temporal locality, and a self-built dataset of 9,192 animal-vocalization
clips cleaned through a three-stage pipeline (PANNs, CLIP, and Silero
voice-activity detection) across 11 classes. The pipeline trains cleanly end-to-end on a
single H100 in ~1h10.
Structural modalities (depth, surface normals) are learned strongly in token space — their
cross-entropy drops the most, on clean pseudo-label targets. Audio learns conditional structure
at the token level (cross-entropy ~1 nat below the marginal codebook entropy), but neither this
nor full-image RGB synthesis lifts to usable cross-modal audio↔vision generation at our scale. We diagnose three specific causes — a train/inference masking
mismatch, an acoustic-only EnCodec tokenizer, and a data-scale gap relative to the
contrastive audio-visual literature — and propose a concrete validation path for each.
The diagnostic, not the generation, is the contribution.
The problem
The goal is bidirectional: a single shared transformer should map a dog's bark to its image, and the image back to its sound — with no objective tailored to either direction.
A unified multimodal model is only as general as the modalities it can host. The 4M family
tokenizes RGB, depth, surface normals, semantic maps, and captions into discrete sequences and
trains a single transformer to predict any subset from any other. Every one of those
modalities is visual, derived from rendered or curated imagery. A real-world temporal
signal — audio — is the natural omission, and the obvious test of whether the recipe
generalizes beyond vision.
Audio is a deliberate stress test. It is temporal rather than spatial, so the random
masking that 4M tailors to spatial token grids lets a decoder copy local context instead of
learning long-range structure. It is high-frequency and sourced from noisy web video, and a
strong neural codec is itself lossy: raw codec tokens are semantically opaque, so the
model must learn class-level meaning on top of acoustic codes.
This frames our hypothesis. A shared transformer can absorb audio at small scale
only if the tokenizer carries semantics and the dataset is large enough for
cross-modal alignment to emerge. We restrict the problem to animal sounds, where each class has
a distinctive acoustic signature and a visually identifiable subject — giving naturally paired
clips and a clean classification oracle.
Method
Architecture
We use nano4M, the course re-implementation of the 4M recipe: a d6-6w512
encoder–decoder transformer (~96M parameters, head dimension 64) that is architecturally
identical to the visual baseline — we add a fifth modality without touching the
network. All modalities share one unified token vocabulary (~50,304 ids); modality and
position embeddings are added to the token embeddings, and the per-modality cross-entropy
is length-normalized so the 512-token audio sequence does not dominate the ~5-token caption.
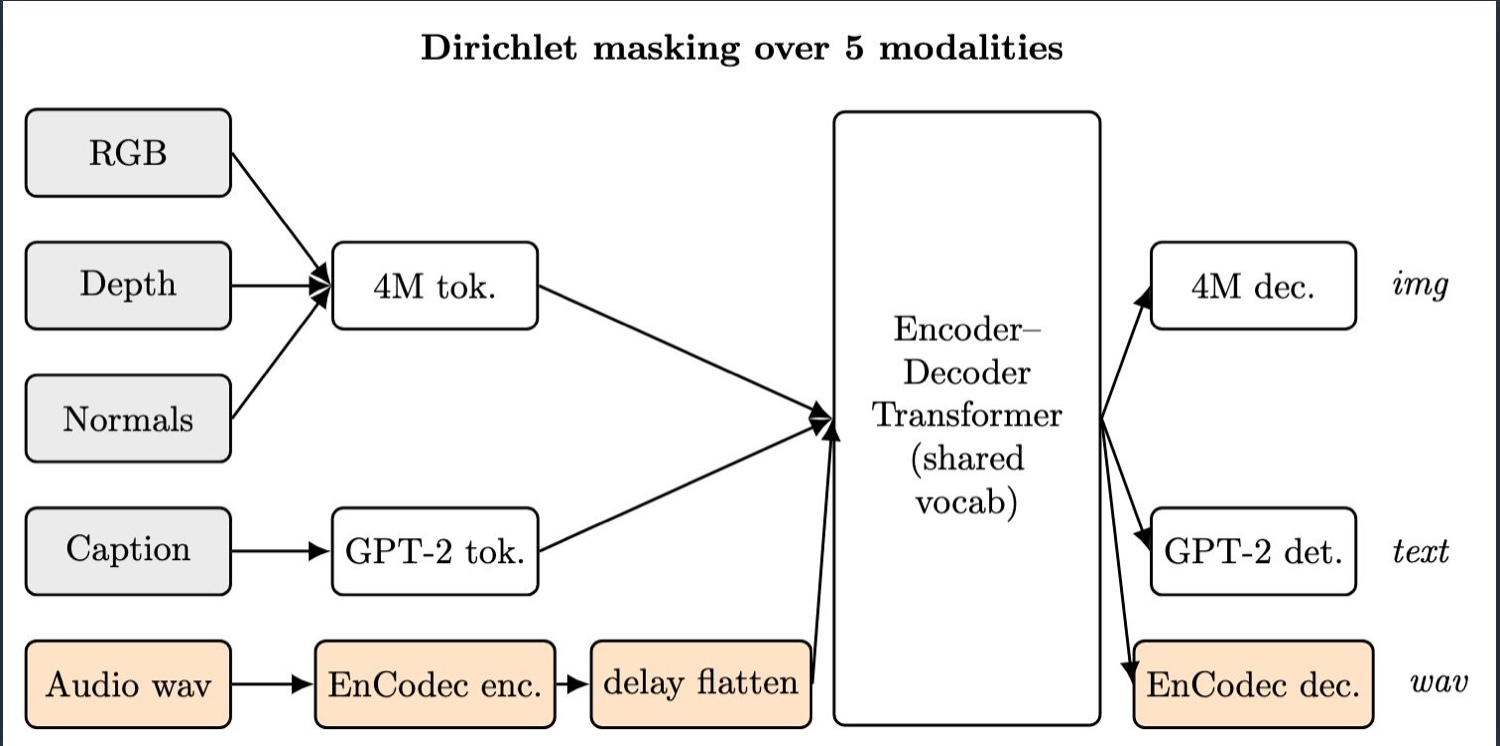
The nano4M-Audio pipeline. A single d6-6w512 encoder–decoder (~96M
parameters) over five tokenized, aligned modality streams sharing one vocabulary: 4M DiVAEs
tokenize RGB / depth / normals, GPT-2 BPE the caption, and EnCodec (with a delay-flatten
pattern) the audio. Dirichlet masking allocates input/target tokens at random across the five
modalities — with span masking on the temporal audio stream — and per-modality loss averaging
keeps the long audio sequence from dominating the short caption.
The five tokenized modalities and their shared-vocabulary footprint.
Modality
Tokenizer
Shape
Vocab
tok_rgb@196
4M-16k DiVAE
[10, 196]
16,384
tok_audio@512
EnCodec 24k, K=2
[10, 512]
2,048
tok_depth@196
DAv2 → 4M-8k
[10, 196]
8,192
tok_normal@196
DSINE → 4M-8k
[10, 196]
8,192
scene_desc
GPT-2 BPE
list
50,304
Audio tokenization
Audio is tokenized with EnCodec at 24 kHz and 1.5 kbps, using K=2 residual-VQ
codebooks at 75 Hz. A ~3.41 s clip yields 256 frames over two codebooks, which we
flatten to a length-512 sequence by interleaving the codebooks (a MusicGen-style
delay/flatten pattern) and offsetting codebook 2 by +1024 so all 2,048 audio ids stay
distinct in the shared vocabulary. We deliberately allocate 512 tokens to audio versus 196
to RGB, prioritizing acoustic context — the project's central focus.
EnCodec optimizes for reconstruction, not semantic identity — a
tension we return to in the diagnostic.
Audio tokenization: a 3.41 s waveform becomes 256 frames over two RVQ codebooks, delay-flattened (codebook 2 offset by +1024) into a single 512-token sequence the transformer consumes alongside the visual tokens.
Dataset construction
We query AudioSet and VGGSound for 11 animal classes (pig, sheep, dog, cat, horse, cow,
chicken, duck, pigeon, coyote, lion). Clips pass three oracle filters: a PANNs audio
score ≥ 0.30 on class-specific indices, a CLIP image–text cosine ≥ 0.25 for the
best of 10 frames, and a Silero voice-activity check that rejects any human speech. After
deduplication across sources we obtain 9,192 clips, split at the
clip level and stratified by class×source into 7,347 / 907 / 938 train / val /
test to prevent leakage. Each clip provides 10 keyframes, decoupling visual diversity
from audio uniqueness; depth and normal targets are pseudo-labeled by Depth-Anything-V2
and DSINE and quantized by 4M-8k DiVAEs.
Three oracle filters (PANNs, CLIP, Silero VAD) clean web-sourced clips before five-modality tokenization, yielding a leakage-free clip-level split.
A real clip — class cat (AudioSet 2REf8hLLYMw @ 30 s), kept by the oracle at PANNs 2.02 · CLIP 0.27 · VAD 0.0.
RGBreal keyframe
AudioEnCodec · 512 tok
“a photo of a cat”
CaptionGPT-2 BPE
One clip end-to-end: the player is its ten real keyframes over the ground-truth audio,
alongside the paired streams it becomes — the RGB keyframe, the EnCodec audio (512 tokens),
and the class caption. The depth and surface-normal targets it is also tokenized into are
shown next.
The two structural modalities are pseudo-labeled before tokenization:
Depth-Anything-V2 for depth and DSINE for surface normals,
each then quantized by a 4M-8k DiVAE. Unlike the noisy web RGB, these targets are clean and
well defined — which is exactly why they become the modalities the model learns most
strongly (What worked).
Training
We train for 18,311 steps (batch 64, ~600M tokens, ~1h10 on a single
H100). Input and target tokens are allocated by 4M Dirichlet masking, with one change:
because audio is temporal, random masking lets the decoder copy adjacent frames, so the
audio stream is masked in contiguous spans (stride 2, aligned to codebook
pairs) for both input and target. We use a cosine schedule (10⁻⁴→10⁻⁶, 916 warmup steps),
AdamW (0.9, 0.95), weight decay 0.05, and gradient clipping 1.0. The final run is fp32: bf16
produced NaNs in the unified 50k-vocab softmax, and fp32 fixed it. The seed is fixed and the
deterministic split is released with the code.
What worked: structural modalities
Depth and surface normals are the modalities the model learns most strongly — their token-level
cross-entropy drops the most, on clean, well-defined targets.
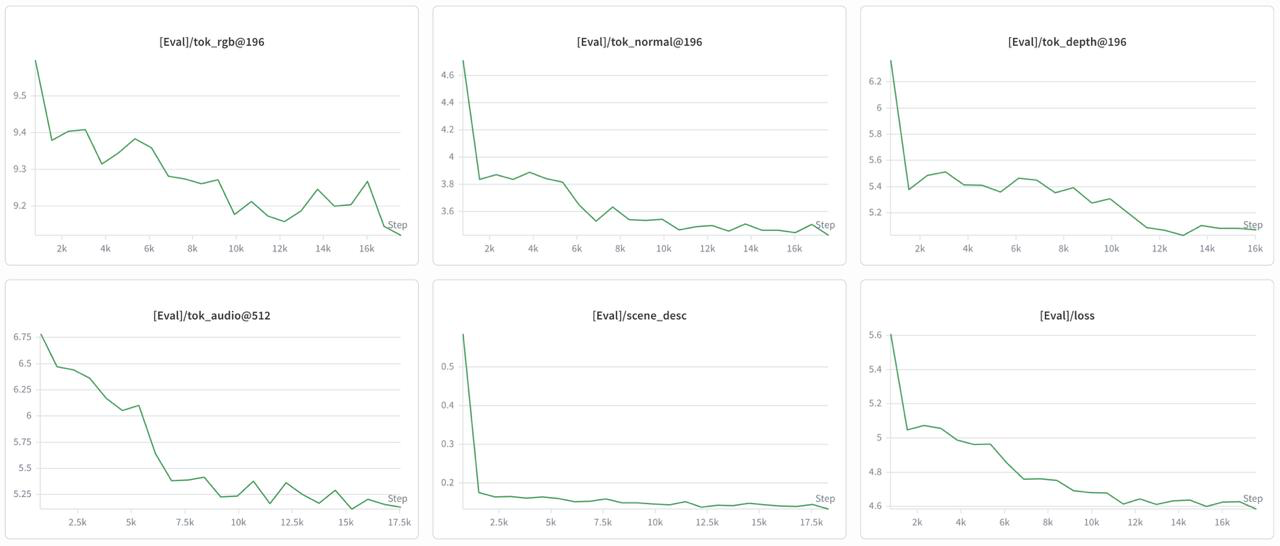
Across 18,311 steps, depth eval cross-entropy falls ~1.2 nats (~6.3 → 5.1) and normals fall
~1.2 nats (~4.7 → 3.5), both monotonically. Training and validation track tightly throughout
and validation never exceeds training — the clip-level split eliminated the frame-level
leakage we saw in early runs. Four of five modalities converge cleanly; RGB is the hardest
and plateaus ~0.45 nats below random, reflecting noisy YouTube imagery and a dense 16k vocab.
Per-modality evaluation cross-entropy over training (Weights & Biases). Audio falls
6.75 → 5.2, depth 6.3 → 5.1, and normals 4.7 → 3.5; the caption
saturates near zero; RGB is the hardest and barely moves. The total loss decreases
monotonically.
Cross-modal generation
The framework predicts structural modalities from RGB well above chance. Generating a full RGB
image from scratch is the hard part — and it stays hard for every conditioning, not only audio.
We probe the canonical 4M directions in token space. RGB→depth and
RGB→normal reach 11% and 18% token-level top-1 — roughly 1000× the 1/8192
random-token baseline — so deterministic structural prediction works. High-entropy image
synthesis is far harder at this scale: both caption→RGB and audio→RGB fail an external ImageNet
ResNet-50 check (≈0% top-5, against ~0.5–5% expected by chance), producing no class-recognizable
image. The limiting factor is RGB synthesis itself, not the conditioning modality.
We therefore read the audio result through what is measurable — token-level
cross-entropy, classification, and retrieval — rather than through generated pixels, which
carry little signal at 10⁴ clips. That analysis is next.
The audio story
Audio is the modality where our central hypothesis is most precisely tested — and where it
partially fails in an informative way.
What the model learns
At the token level, audio genuinely learns. Its eval cross-entropy settles at
5.2 nats, below the empirical marginal entropy of the EnCodec codebook on
our data (~6.2 nats, itself below log 2,048 = 7.62 because the token
distribution is far from uniform). A model that ignored every other modality and predicted
from the marginal would score 6.2; ours scores 5.2 — about 1 nat of conditional
structure per audio token. This is real, non-trivial cross-modal learning, not
memorization.
The model captures ~1 nat of conditional information per audio token beyond a marginal predictor — measurable token-level learning.
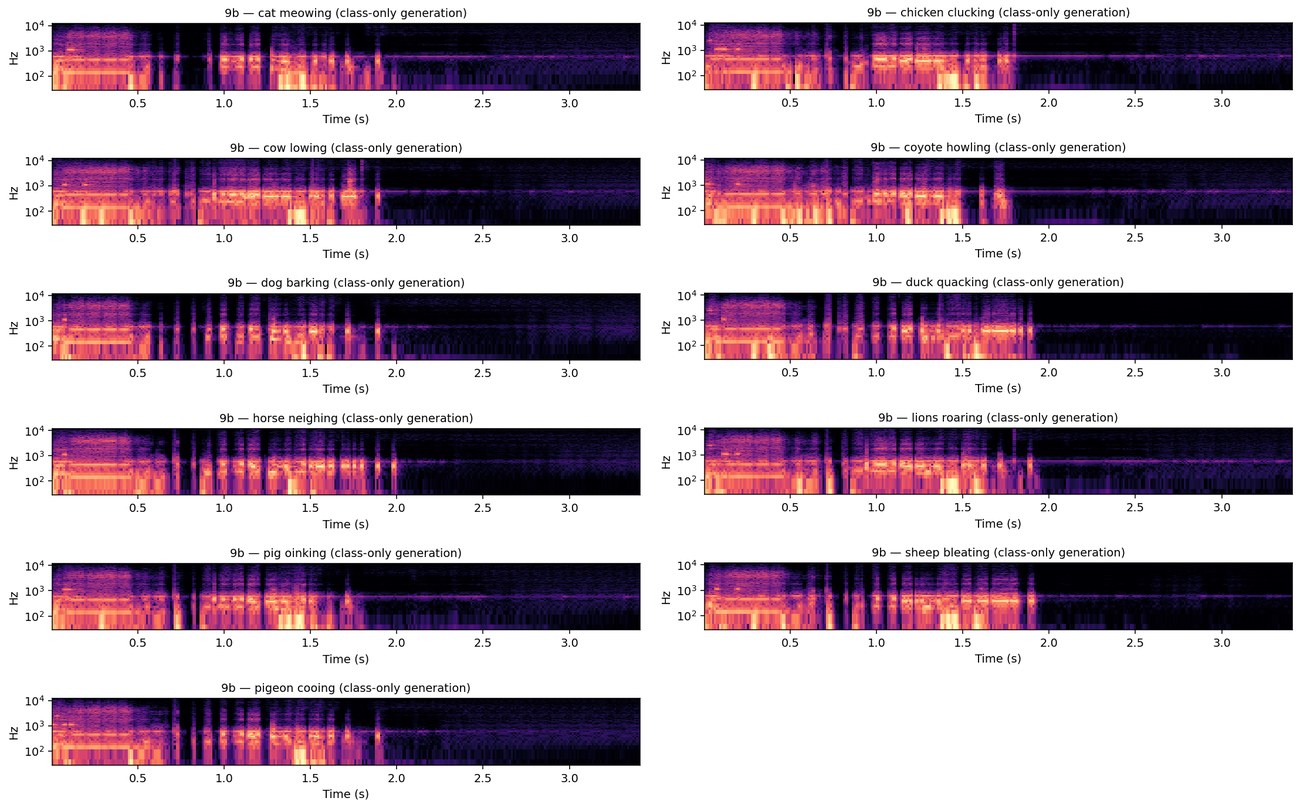
Audio generated from the class label alone (audio fully masked,
MaskGIT-decoded, EnCodec-vocoded), one panel per class. There is genuine spectral
content — broadband energy with formant-like banding — but the eleven classes share a
near-identical burst-then-decay envelope: the token-level signal does not separate into
class-distinct sounds. This is the mode collapse the diagnostic below characterises.
Where it stops
That token-level signal does not lift to cross-modal behavior. Audio-only class prediction
reaches 10.4% top-1 (chance 9.1%) and cross-modal retrieval peaks at R@5 = 4.5% (chance
2.5%). Three acoustically distinct classes are clearly learned — pig and sheep at 5.1× chance,
dog at 2.4× — while ambiguous classes collapse systematically onto neighbours (the bird
cluster chicken/duck/pigeon, the canid cluster coyote/lion→dog). Generation mode-collapses
in both directions, and a memorization probe is decisive: on audio-suffix completion, train
accuracy (2.9%) ~test accuracy (4.1%), so the model does not even memorize the training set.
Audio behavior against explicit random baselines (938-clip test set).
Probe
Model
Random
Audio → class, top-1
10.4%
9.1%
Audio → class, top-5
48.4%
45.5%
Best cross-modal retrieval, R@5
4.5%
2.5%
Audio → RGB, ImageNet top-5
0%
~5%
Memorization probe (train / test)
2.9% / 4.1%
—
The gap between "1 nat of conditional structure learned" and "generated audio
is mode-collapsed" is the central observation we set out to characterize — a sharp
asymmetry between what the encoder represents and what the decoder can generate.
Listen for yourself
Six classes spanning the best- and worst-recovered cases, three clips each.
Ground truth is the original recording.
Continuation is the charitable probe: the model hears the first 80% of the
audio tokens (plus the paired RGB and caption) and predicts only the final 20% — so the
opening is real and the tail is the model's. Class-only generation is the
hardest setting: the entire audio stream is masked and decoded from the class label alone.
Ground truth is the untouched recording; the model's outputs (continuation and class-only
generation) are EnCodec-decoded, so they sound band-limited by the codec. Listen for the
diversity across ground-truth clips versus the flattened, near-identical character the
generations collapse to — the audible signature of the mode collapse the diagnostic identifies.
Class
Ground truth
Continuation hears 80%, predicts 20%
Class-only generation
Note
Pig
Best-recovered class — 5.1× chance in audio→class.
Sheep
Best-recovered class — 5.1× chance.
Dog
Learned at 2.4× chance; attractor for the canid cluster.
Cat
Acts as an attractor class in the confusion structure.
Chicken
Bird cluster — collapses with duck and pigeon.
Horse
Never recovered in audio→class (0% top-1).
Continuation conditions on the first 80% of the audio plus the paired RGB and caption;
class-only generation conditions on the label alone (audio fully masked). Compare the
spectral diversity of the ground-truth clips against the consistent flattened character the
model's outputs collapse to.
Diagnostic and path forward
We isolate three causes, each backed by direct evidence and each mapped to a concrete,
validatable next experiment.
Cause 1 — Acoustic ≠ semantic
EnCodec is a neural codec optimized for waveform reconstruction. Its tokens encode
timbre, pitch, and energy envelope — not class identity. Small token errors decode to
similar textures, so the model learns acoustic regularities it cannot promote to
categories. This reconciles the 1-nat conditional gain with near-chance classification.
Lever: replace EnCodec with a semantically grounded
tokenizer (SpeechTokenizer, MERT). Validation: re-run on the same data; expect
audio classification to lift to ≥3× random.
Cause 2 — Train/inference mismatch
Random Dirichlet masking almost never presents the "predict an entire modality from
another alone" condition, so single-source MaskGIT decoding is out of distribution —
which is exactly why adding more conditioning reduces the generated energy
spread (75% → 58% of ground truth) instead of helping.
Lever: asymmetric / curriculum / modality-dropout masking
that explicitly trains single-source→full-modality prediction. Validation:
expect added context to help, not hurt, the energy spread.
Cause 3 — Below the emergence threshold
Contrastive audio-visual learning works at 10⁵–10⁶ paired clips (AudioCLIP, CLAP,
ImageBind); we operate at ~10⁴, roughly 1000× below 4M's training scale. The curves
saturate cleanly with val ≤ train throughout, so more compute on this data would not
help — the binding limit is data quantity.
Lever: scale to full VGGSound (~150k clips) and a larger
model. Validation: a 10k → 30k → 100k scan to locate the emergence threshold.
We expect the semantic tokenizer to lift classification, the masking fix to repair the
out-of-distribution generation, and the data scale to lift retrieval — together closing the
cross-modal generation gap. A quantitative generation metric (Fréchet Audio Distance via a
CLAP embedder) would replace informal listening. The contribution of this project is the
precise diagnostic and the validated framework; the next steps are concrete and well-scoped.